Nlp And Rnns
August 14, 2015Andrej Karpathy wrote great post on teaching a Recurrent Neural Net structure of the english language. Let's try to run few experiments based on the minimal implementation of the RNN algorithm. The code for the experiments is in this git.
An RNN cell is described by the following equations:
\[ h_{in} = W_{xh} x + W_{hh} h + b_{h} \] \[ h' = f( h_{in} ) \] \[ y = W_{xh} h' + b_{y} \]
And with softmax output:
\[ p_i = \frac{ e^{y_i} }{ \sum{ e^{y_i} } } \]
Original implementation of the RNN uses tanh as an activation function \(f( h_{in} )\). The backprogation through tanh therefore is:
\[ dh_{raw} = (1 - \tanh^2( h_{in} )) dh' \]
I was curious how Rectified Linear Unit (RELU) would perform during text recovery by RNN. The forward pass in case of RELU is trivial:
\[ h' = \max( 0, W_{xh} x + W_{hh} h + b_{h} ) \]
The backward pass is not too complicated either:
\[ dh_{raw} = sig( h_{in} ) dh \]
The output from the two comparable nets looks quite interesting (the net was trained on Paul Graham essays). This is what we get after 2,078,400 iterations from tanh version:
he reems and gens Alance your fing dation such in is or dereacted to next if you've about on surpricate shof you've work like that the moypravisy 5 9-be idess Leforter, because is that atered as they
A bit bubly, isn't it? Here's the RELU version after the same number of iterations:
hat it found lices like. But language job sharen relras answeaking happens and by business could want you explane-- not just thacker durery is decide the do you be meaged to figure finiction it don't
Still bubly, albeit a bit less. The following chart shows loss as a function of iterations.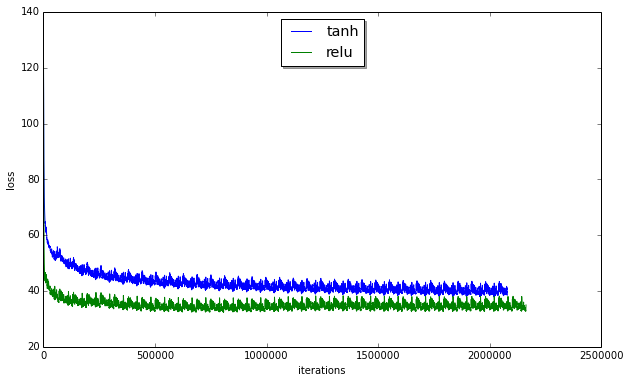
What's interesting about RELUs is that they converge much faster than tanh, however at the begining I was getting lot's of overflow errors. Clipping the vectors before softmax allowed to remove this problem.